
A Gentle Guide to LSTM Network
This article will assist you to know about the problems of conventional RNNs, namely, the vanishing and exploding gradients and provides a convenient solution to these issues in the form of Long Short-Term Memory (LSTM).
Introduction:
LSTM networks are an extension of recurrent neural networks (RNNs) fundamentally introduced to handle situations where RNNs fail. RNNis a network that works on the present input by taking into consideration the previous output (feedback) and storing in its memory for a short period of time (short-term memory). RNN fails to store information for a longer period of time. RNNs are absolutely incapable of handling information stored quite a long time ago “long-term dependencies”. Second, there is no better control on which part of the context needs to be carried forward and how much of the past needs to be ‘forgotten’. Few more issues with RNNs are exploding and vanishing gradients which occur during the training process of a network through backtracking. Thus, Long Short-Term Memory (LSTM) was brought into the image. It has been so designed that the vanishing gradient problem is almost totally removed, while the training model is left unaltered. LSTMs offers a large range of parameters such as learning rates, and input and output biases. Hence, no need for any adjustments. The complexity to update each and every weight is reduced to O(1) with LSTMs, similar to that of Back Propagation Through Time (BPTT), which is an advantage.
Architecture:
The main difference between the architectures of RNNs and LSTMs is that the hidden layer of LSTM is a gated unit or gated cell. It comprises of four layers that interact with one another in a way to produce the output of that cell and the cell state. The output and cell state are being passed onto the next hidden layer. RNNs has only single neural net layer of tanh, whereas LSTMs comprises of three logistic sigmoid gates and one tanh layer. Gates have been implemented in order to limit the information that is passed through the cell. They decide which part of the information will be needed by the next cell and which part is to be discarded. The output is typically in the range of 0-1 where ‘0’ means ‘reject all’ and ‘1’ means ‘include all’.
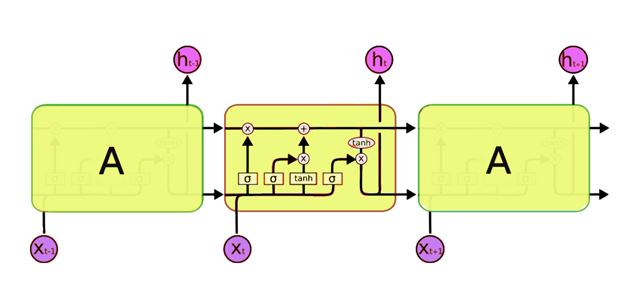
A typical LSTM network is comprising of different memory blocks called cells
(the rectangular shape in the image). The cell state and the hidden state are two states that are being transferred to the next cell. The memory blocks are accountable for memorizing things and through gates manipulations to this memory is done. Let’s discuss of them below.
Forget Gate
A forget gate is liable for removing information from the cell state. The information that is no longer needed for the LSTM to understand things is removed via multiplication of a filter. This is required for upgrading the performance of the LSTM network.
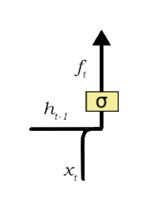
This gate takes in two inputs they are h_t-1 and x_t.
h_t-1 is the hidden state or the output of the previous cell and x_t is the input at that particular time step. The specified inputs are multiplied by the weight matrices and a bias is added. Following this, the sigmoid function is applied to this value where it outputs a vector, with values ranging from 0 to 1, corresponding to each number in the cell state. If the function results ‘0’ for a particular value, it indicates that the forget gate wants the cell state to forget that piece of information completely. Similarly, output ‘1’ means that the forget gate wants to store that entire piece of information. The sigmoid function’s vector output is multiplied to the cell state.
Input Gate
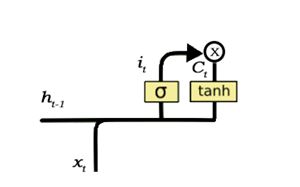
The input gate is accountable for the addition of information to the cell state. This addition of information is fundamentally three-step process as seen from the above diagram.
- Regulating what values should be added to the cell state by involving a sigmoid function. This is same as the forget gate and acts as a filter for all the information from h_t-1 and x_t.
- Creating a vector consisting of all possible values that can be added (as perceived from h_t-1 and x_t) to the cell state. This is done utilizing the tanh function, which results values from -1 to +1.
- The created vector (the tanh function) is then multiplied by the value of the regulatory filter (the sigmoid gate) and then adding this useful information to the cell state by addition operation.
Once this three-step process is done, we make sure that only that information is added to the cell state that is important and is not redundant.
Output Gate
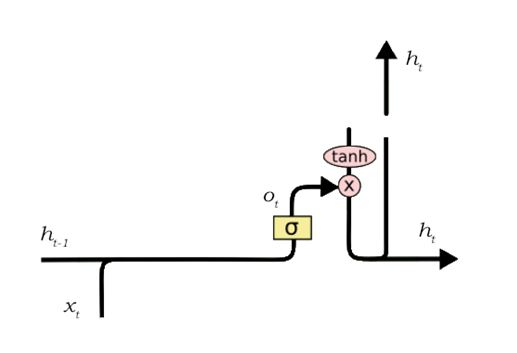
The functioning of an output gate can again be separated down to three steps:
- After applying tanh function to the cell state creating a vector, thereby scaling the values to the range -1 to +1.
- Using the values of h_t-1 and x_ta filter can control the values that need to be output from the vector created above. This filter again uses a sigmoid function.
- Vector created in step 1 is Multiplied by the value of this regulatory filter, and sending it out as an output and furthermore to the hidden state of the next cell.
The filter in the above instance will make sure that it diminishes each and every other value but ‘Bob’. Hence, the filter should be built on the input and hidden state values and is applied on the cell state vector.


