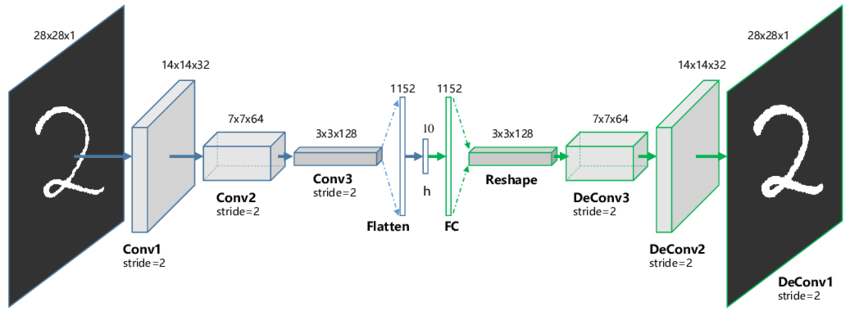
Explain about Convolutional autoencoder?
Ans: Convolutional Autoencoders use the convolution operator to exploit this observation. Rather than manually engineer convolutional filters we let the model learn the optimal filters that minimize the reconstruction error. These filters can then be used in any computer vision task. Convolutional Autoencoders are the state of art tools for unsupervised learning of convolutional filters. Once these filters have been learned, they can be applied to any input to extract features. These features can be used to do any task that requires a compact representation of the input, like classification.
CAEs are a type of Convolutional Neural Networks (CNNs). The main difference between the common interpretation of CNN and CAE is that the formers are trained end to end to learn filters and combine features with the aim of classifying their input. The latter are trained only to learn filters able to extract features that can be used to reconstruct the input.
CAEs, due to their convolutional nature, scale well to accurate sized high dimensional images as the number of parameters required to produce an activation map is always the same, no matter what the size of the input is. Therefore, CAEs are general purpose feature extractors differently from AEs that completely ignore the 2D image structure. Actually, in AEs the image must be unrolled into a single vector and the network must be built following the constraint on the number of inputs.


