What are the major types of different Regression methods in Machine Learning?
Regression Analysis is all about to find the relationship between Dependent Variables and Independent Variables. There are different kind of Regression techniques based upon the factors or metrics like number of independent variables, type of dependent variable and shape of Regression line. There are 7 most commonly used methods of regression Analysis or methods in machine Learning. They are
- Linear Regression
- Logistic Regression
- Polynomial Regression
- Step wise Regression
- Ridge Regression
- Lasso Regression
- Elastic Net Regression
Linear Regression
Let’s understand each type of Regression briefly
It is one of the most widely used technique in regressions models. Generally, in Linear Regression, Dependent variable is continuous where as Independent Variable may be continuous or discrete. It establishes the relationship between one dependent variable and one or more independent variable using best fit straight line which is also termed as Linear.
Linear Regression is usually represented by the mathematical equation Y=a + b*X + e.
Where a is the intercept, b is slope of the line and e is the error. This equation is used to predict the value of target variable or dependent variable based on predictor variable or independent variable. Linear regression also has two types which are simple linear regression and multi linear regression.
Logistic Regression
Simple Linear Regression finds the relation ship between single dependent and Independent variables. Where as Multi linear regression establishes the relationship between multiple Independent variables and Dependent variable.
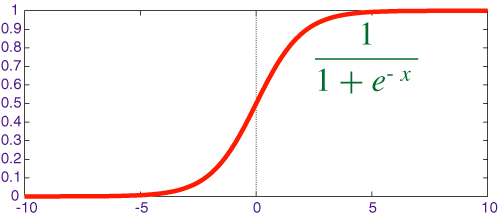
Logistic regression is used to find the probability of event=Success and Failure. Logistic regression is used when the dependent variable is binary in nature. The value of Y ranges from 0 to 1.
Polynomial Regression
Logistic regression doesn’t require linear relationship between dependent and independent variables. It can handle various types of relationships as it applies a non-linear log transformation to the predicted odds ratio.
Polynomial Regression is termed as polynomial as the power of independent variable is more than or greater than one.
y=a+ b*x^2
Step wise Regression
In the Polynomial Regression, the best fit line may not be a straight line, it can be a curve line which can fit the model perfectly.
This type of Regression is used when we have multiple independent variables. In step wise Regression, the selection of independent variable is done automatically, any human intervention is not required. Stepwise regression basically fits the regression model by adding/dropping co-variates one at a time based on a specified criterion.
- Stepwise regression adds and removes predictors or independent variables as needed for each step.
- Forward selection starts with most significant predictor in the model and adds variable for each step.
- Backward elimination starts with all predictors in the model and removes the least significant variable for each step.
Ridge Regression
The aim of the step wise regression technique is to maximize the prediction power with minimum number of predictor variables.
Ridge Regression is used when the model is suffering from multicollinearity which means independent variable are highly collinearity. In multicollinearity, even though the least squares estimates are unbiased, their variances are large which leads to the deviation of observed value far from the true value. By adding a degree of bias to the regression estimates, ridge regression reduces the standard errors.
Y= a+ b*x
Lasso Regression
In a linear equation, prediction errors can be decomposed into two sub components. First is due to the biased and second is due to the variance. Prediction error can occur due to any one of these two or both components.
Lasso is another variation, in which the above function is minimized. It is clear that this variation differs from ridge regression only in penalizing the high coefficients. It uses |βj|(modulus)instead of squares of β, as its penalty. In statistics, this isknown as the L1 norm.

Consider there are 2 parameters in a given problem. Then according to above formulation, the ridge regression is expressed by β1² + β2² ≤ s. This implies that ridge regression coefficients have the smallest RSS (loss function) for all points that lie within the circle given by β1² + β2² ≤ s.
Elastic Net Regression
Similarly, for lasso, the equation becomes, |β1|+|β2|≤ s. This implies that lasso coefficients have the smallest RSS (loss function) for all points that lie within the diamond given by |β1|+|β2|≤ s.
Elastic Net is hybrid of Lasso and Ridge Regression techniques. It is trained with L1 and L2 prior as regularizes. Elastic-net is useful when there are multiple features which are correlated. Lasso is likely to pick one of these at random, while elastic-net is likely to pick both.
A practical advantage of trading-off between Lasso and Ridge is that, it allows Elastic-Net to inherit some of Ridge’s stability under rotation.