
Extracting insights from free text
Text Mining the most complex analysis in the industry of analytics. In text mining, we deal with unstructured data. We have not plainly defined observation and variables i.e., rows and columns. So, you need to first convert this unstructured data into a structured dataset for doing any sort of analytics work, and then proceed with normal modelling framework. The extra step of changing an unstructured data into a structured format is simplified by a Word dictionary to do any kind of information extraction. To do a sentiment analysis dictionary is easily available on web world. But, for some precise analysis you need to create a dictionary of your own.
This article starts from the very basic level to help anyone, who might not have ever worked on text mining. Let’s consider a business case to explain this framework and the practical usage.
Business Problem
Consider are the proprietor of Metrro cash n carry. Metrro tied up with Barcllays bank to launch co-branded cards. Metrro and Barcllay have just entered into a contract to share transactions data. Barcllays will share all transaction details done on their credit card on any retail store. Metrro has to share all transaction done by any credit card on their stores. You wanted to use this data to track your high value customers shopping other than Metrro.
For you need to get information from the free transactions text available on Barcllays transaction data. For example, a transaction with free text “Payment made to Messy” should be tagged as transaction made to the retail store “Messy”. When we have the frequency of transactions at retail stores for Metrro high value customers, you can analyze the motive of this customer outflow by associating services between Metrro and the other retail store.
Unstructured data mining framework
The dictionary we need looks like a very niche dictionary in this business problem. We should recognize all retail store names from the transaction free text. Probability of this dictionary being reliable and such a dictionary being available is very low. Hence,to score our entire data we need to create such a dictionary.
Below is a framework you can follow to create this dictionary :
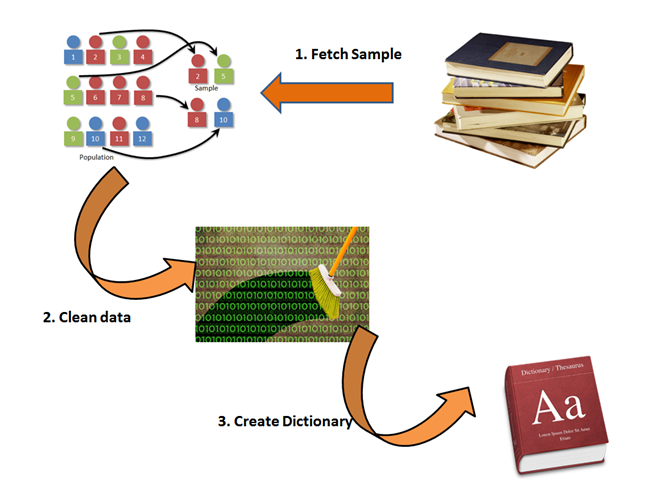
Step 1: The task of analyzing the entire text data is impossible, hence we take a random/stratified sample to build a dictionary.
Step 2: We capture the real essence of the text available by cleaning the data. For example, Maccy’s ,maccy and Maccyto be counted as single word. Also, we has to eliminates topwords of English dictionary.
Step 3: Once after cleaning the text, extract the most frequently occurring words. If cleaning was not done,just imagine how non conclusive results would be. Manually identify the frequently occurring words as identifiers. This will form your dictionary.
It is now time to score your entire dataset from the final dictionary. Below is a framework you can follow to score your dataset :
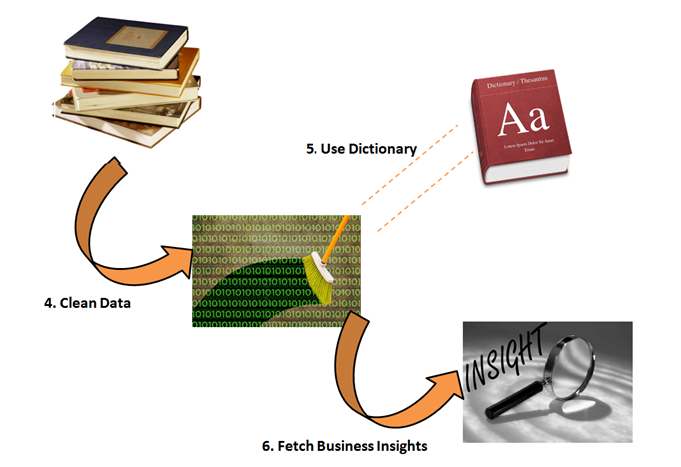
Step 4: Time has come to clean the entire data-set. This is to make sure that the dictionary we have created in step 3 works on this entire dataset.
Step 5: We can categorize each transaction statement using the dictionary.
Step 6: Once we have tags of category on each transaction statement, we can summarize the entire dataset to fetch business insights and frame business strategy.
Hope this article helped on how to do text mining on real life problem statement.


