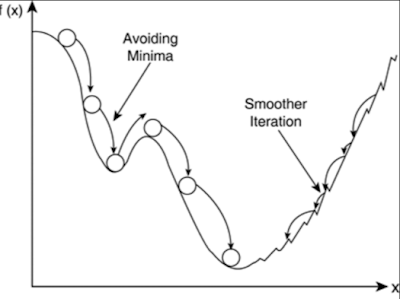
How can you avoid local minima to achieve the minimized loss function?
Ans: We can try to prevent our loss function from getting stuck in a local minima by providing a momentum value. So, it provides a basic impulse to the loss function in a specific direction and helps the function avoid narrow or small local minima.
Use stochastic gradient descent. The idea is to not use the exact gradient, but use a noisy estimate of the gradient, a random gradient whose expected value is the true gradient because we are using a noisy gradient, we can move in directions that are different from the gradient. This sometimes takes us away from a nearby local minimum, and can have the effect of preventing us from getting trapped in small local minimum.
Batch size in Neural Networks
This fits very well with training deep networks, because the true gradient depends on all the training data, and is very expensive to compute. By computing a gradient estimate using just some of the training data, we can much more efficiently produce a noisy estimate of the gradient.


