
K-means Clustering- The Most Comprehensive Guide
What is Clustering?
Clustering technique is the process of dividing the entire data into groups also known as clusters depending on the patterns in the data.
K-Means Clustering is an unsupervised machine learning algorithm. In divergence to traditional supervised machine learning algorithms, K-Means tries to classify data without having initially been trained with labeled data. Once the algorithm has been run and the groups are characterized, any new data can be effectively assigned to the most pertinent group.
The real-world applications of K-Means comprise:
Customer profiling
One of the widest applications of clustering is customer segmentation. And it isn’t simply restricted to banking. This methodology is across functions, including telecom, e-commerce, sports, advertising, sales, etc.
Document segmentation
Suppose you have multiple documents and you need to group similar documents together. Clustering helps to group similar documents such that they are in the same clusters.
Image segmentation
We can likewise use clustering to accomplish image segmentation. Here, we try to club same pixels in the image together. We can perform clustering to create clusters having similar pixels in the same group.
Recommendation engines
Suppose you want to recommend songs to your friends. You can check at the songs liked by that person and then apply clustering to find similar songs and finally recommend the most similar songs.
let’s have a look at the properties of these clusters.
Property 1:
All the data points in a cluster should be alike with each other. Consider using the above example:
Property 2:
The data points from dissimilar clusters should be as different as possible.
Which of the above cases do you think will give the better clusters? Consider below example for illustration.
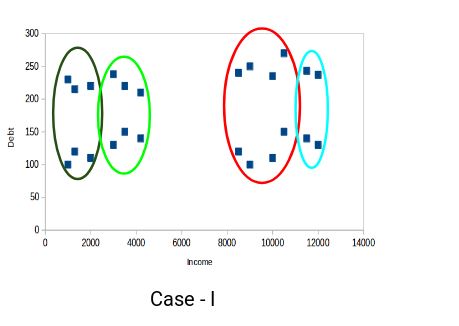
Points in the red and blue clusters are pretty similar to each other. The top four points in the red cluster have similar properties as that of the top two customers in the blue cluster in the sense that they have high income and high debt value. Here, we have clustered them differently. Whereas, if you look at case II:
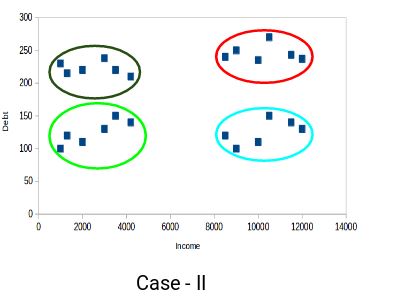
Points in the red cluster are totally different from the points in the blue cluster. All the points in the red cluster have high income and high debt and points in the blue cluster have high income and low debt value. It is clear that, we have a better clustering of points in this case.
Hence, data points from different clusters has to be as different as possible from each other to have more meaningful clusters.
Understanding the Different Evaluation Metrics for Clustering
The main goal of clustering is not only to make clusters, but to make good and meaningful ones. It is clear in the below example:
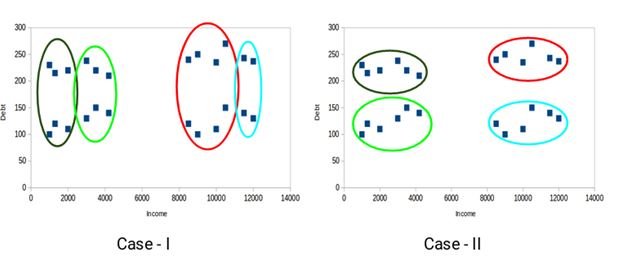
In the above example, we used only two features and hence it is easy for us to visualize and decide which of these clusters is better.
Lamentably, that’s not how real-world situations work. We will have to work with huge features. Let’s take the customer segmentation model– we will have features like customer’s income, occupation, gender, age, and many more. Visualizing all these features together and choosing better and meaningful clusters would not be possible for us.
This is the place where we can make use of evaluation metrics. Let’s discuss a few of them and see how we can use them to evaluate the quality of our groups.
Inertia
Recall the first property of clusters we covered previously. This is evaluated by inertia and it tells us how far the points inside a cluster are. So, inertia really computes the sum of distances of all the points within a cluster from the centroid of that cluster.
We compute this for all the clusters and the last inertial value is the sum of all these distances. This distance within the clusters is acknowledged as intracluster distance. So, inertia gives us the sum of intracluster distances:
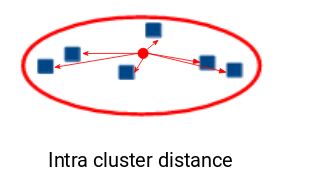
As we need the points within the same cluster to be similar to one another and hence, the distance between them should be as low as possible.
Dunn Index
We now know that inertia attempts to limit the intracluster distance. It is attempting to make more compact clusters.
Consider this way – if the distance between the centroid of a cluster and the points in that cluster is little, it implies that the points are nearer to each other. Thus, inertia ensures that the first property of clusters is fulfilled. But it does not care of the second property – that different clusters have to be as different from each other as possible.
This is the place where Dunn index can come into act.
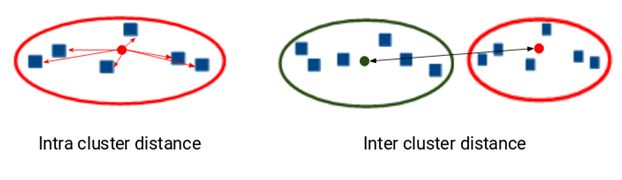
In addition to the distance between the centroid and points, the Dunn index also takes into account the distance between two clusters. This distance between the centroids of two different clusters is acknowledged as inter-cluster distance. Below is the formula of the Dunn index:
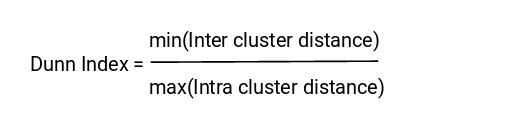
When the value of the Dunn index is more, the clusters will be that better. Let’s understand the perception behind Dunn index:
In order to have maximum value of the Dunn index, the numerator need to be maximum and the denominator need to be minimum.
Introduction to K-Means Clustering
K-means is a centroid-based algorithm, or a distance-based algorithm, where we compute the distances to assign a point to a cluster. In K-Means, each cluster is related with a centroid.
Let’s consider an example to understand how K-Means actually works:

We have 8 points and we want to perform k-means to create clusters for these points. Here’s the process to do it.
Step 1: Choose the k number of clusters
The initial step in k-means is to choose the number of clusters, k.
Step 2: Choose k random points from the data as centroids
Next, we randomly choose the centroid for each cluster. Let’s say if we want to have 2 clusters, hence k is equal to 2 here. We then randomly choose the centroid:
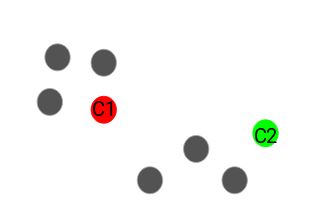
Here, the red and green circles denote the centroid for these clusters.
Step 3: Assign all the points to the cluster centroid which is close
Once we have initialized the centroids, we allocate each point to the closest cluster centroid:
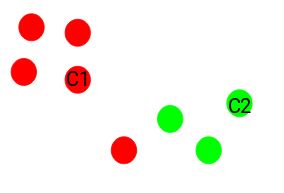
Above you can see that the points that are closer to the red point are assigned to the red cluster whereas the points that are closer to the green point are assigned to the green cluster.
Step 4: Recompute the centroids of newly formed clusters
Now, once we have allocated all of the points to either cluster, the next step is to calculate the centroids of newly formed clusters:
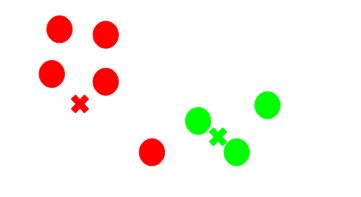
Here, the red and green cross symbols are the new centroids.
Step 5: Repeat steps 3 and 4
We then repeat steps 3 and 4:
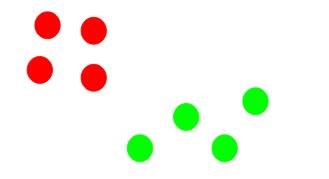
Stopping Criteria for K-Means Clustering
There are basically three stopping criteria that can be adopted to stop the K-means algorithm:
- Centroids of newly formed clusters do not vary
- Points remain in the identical cluster
- Maximum number of iterations are touched
We can stop the algorithm if the centroids of newly formed clusters are not varying. Even after various iterations, if we are getting the similar centroids for all the clusters, we can say that the algorithm is not learning any new pattern and it is an indication to stop the training.
Another clear sign that we should stop the training process if the points remain in the same cluster even after subsequent training of the algorithm for various iterations.
At last, we can stop the training if the maximum number of iterations is reached. Assume if we have set the number of iterations as 200. The process will repeat for 200 iterations before stopping.


