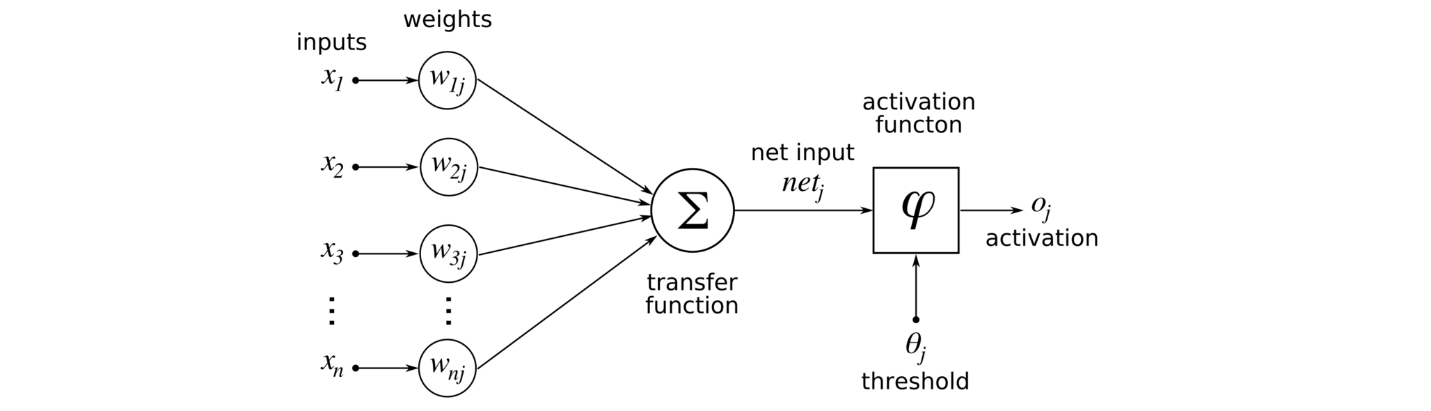
Activation functions in Deep learning
Generally , These functions are mainly used in Deep Learning models especially Artificial Neural Networks. Basically the activation functions decides weather the neuron activated or not.
![]()
Activation functions is used to mapping the complicated and non-linear functions between the input and output signals. Then the output signal is input to the next layer.without activation function we can’t do a non-linear transformations because there is no activation function the weights and biases do linear transformation.we want to do a image classification and language translation, then the linear transformation is not suitable that’s why we are going with non-linear transformation.
Here deep learning models are very high complicated , high dimensional , large data and number of hidden layers for this the activation function make sense between the input and output signals.the one more important feature of activation function is it should be differential which we used in back propagation optimization techniques that will compute the loss with respect to the Weights and biases.
There are different types of activation functions are there. They are
1. Linear
2. Sigmoid
3. Tanh
4. Relu
5. LeakyRelu
6. Softmax
1.Linear:
The linear activation is straight line and the activation is proportional to the input.

It gives a range of activation’s that’s why it is not a binary function. The disadvantage of this function is the derivative of linear function is constant then the gradient is also a constant so there is no relationship with input.
2. Sigmoid:
It is very easy to understand and the sigmoid function is in the form of
F(x) = 1/1+exp(-x)
And the range is in between the 0 and 1. It takes a real values as inputs and give the output values in 0 and 1. And it is a monotonic and continuously differential and has a fixed output range. The main disadvantage of the sigmoid function is vanishing gradients and its not a zero centered and the gradient updates are far in different directions. It makes the optimization hard.
different directions. It makes the optimization hard.

3. TanH Function:
The range of the TanH function is [-1,1] and the formula is
F(x) = 1-exp(-2x) / 1+exp(-2x)
And it is a zero centered and the output is in between [-1 , 1] I,e; -1 < output < 1 , then the optimization is easy so compared to sigmoid TanH is more preferably. The Tanh is also suffers from vanishing gradients.

4. Relu (Rectified Linear Unit):
Now a days , this is the very popular activation function in deep learning models because this is six times improvement in convergence from tanH function.
In this if any negative input receives it will returns 0 and any positive value (x) it will return back the value.
I,e F(x) = max(0,x)

In this we overcome the vanishing gradients but it has a limitation which is only used in hidden layers.and another problem is some gradients are damaged during training and sometime die. This can be overcome by LeakyRelu activation function.
5. LeakyRelu:
LeakyRelu is the extension of Relu activation function. In relu function sometimes number of neurons are died which affects the performance of the model. This can be corrected by LeakyRelu by introducing a small slope which keep the updates alive.
If it gives x>0 it will return x and it will gives x<=0 it will return x along with some constant value Z I,e xZ. The standard value of the Z is 0.01.

6. SoftMax:
It is very similar to the sigmoid function but only difference is sigmoid is only for two class classification but the Softmax is multiple class classification. The range of softmax function is [0,1]. Softmax function would squash the output for each class between 0 and 1 and divided by the sum of outputs so the output of softmax is a probability distribution.This will be mainly used in output layer.


Finally we can conclude that softmax function is used for multi-class classification and must be used in output layer.