Basics of object Detection Algorithms
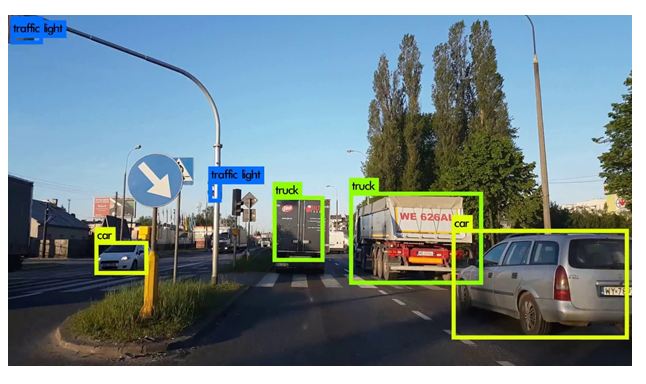
In the field of deep learning, the sub-direction is called Object Detection which is used to identifying the objects through the pictures, videos and webcam feed.

Now-a-days the “Object Detection” is used in everywhere and the use cases are endless. For example are tracking objects, Video surveillance, Pedestrian detection, Anomaly detection, People Counting, Self-driving cars or Face detection, the list goes on.

In this we are having the three types of main Object Detection algorithms. They are;
- Faster R-CNN
- YOLO
- SSD
Apart from these three we are having many more algorithms which found in online. But every algorithm have its pros and cons from that I we can figure out which one we can use.

R-CNN :
R-CNN (Region R-CNN) is a state of art model of CNN based deep learning object detection approaches. In this we are having R-CNN and faster R-CNN for faster speed object detection.
Basically, for each and every image, there is a sliding window to search every position within the image as shown in below. It look likes it is a simple solution right. However, different objects or same kind of objects can have the different aspect ratios and different sizes depending on the specific object size and distance from the camera. And the sizes of every different image also affect the effective window size. So once observe this process it will be extremely slow if we use deep learning CNN for image classification at each location.

1. Here R-CNN uses a selective search to generate the 2000 bounding boxes for the every image classification.
2. For each bounding box, image classification is done through CNN.
3. And finally each bounding box is strained using regression.

Disadvantages of R-CNN.
1. In this we have to classify the 2000 region proposals in every image and it takes a lot of time to train the network.
2. In real time it cannot be implemented because it takes more number of seconds (approximately 47 seconds) for every test image.
3. Basically selective search algorithm has no learning process because it is a fixed algorithm.so it will leads to the bad generation of candidate region proposals.
Fast R-CNN:

The Faster R-CNN is also very similar to the R-CNN algorithm. But instead of feeding the region proposals to CNN, we can feed the input image directly to CNN and generate the convolution feature map and from this convolution feature map we can easily identify the region of proposals and muffle them into squares and we can reshape them into fixed size by using RoI pooling layer that it can be fed into fully connected layer. In this from RoI vector we can use softmax layer to predict the class of proposed region.
The advantages of Fast R-CNN:
1. In this faster R-CNN we don’t have to feed the 2000 regions to convolution neural networks at any time.
2. The convolution map is done only once per image and feature map is generated.
Faster R-CNN:

The faster R-CNN is also similar to the fast R-CNN; in fast R-CNN we can give the input as image which provides a convolution feature map. In Faster R-CNN also we can give the image as input but instead of selective search algorithm we can use separate network to predict the region proposals. This predicted region proposals are reshaped by using RoI polling layer then used to classify the image within the proposed region. In this Faster R-CNN the Anchors are play vital role. The Anchors are nothing but the boxes. In Faster R-CNN we can have the 9 anchors default. The below image shows the 9 anchors at position of an image (320, 320) and the size is (600,800)

YOLO (YOU ONLY LOOK ONCE):

The all previous object detection algorithms are using region proposals to detect the object within the image and this network does not look at the complete image. Instead of this we can split the image into parts which containing high probabilities of containing the object. YOLO or You Only Look Once is the one type of object detection algorithm is different from the region based detection algorithms. In this YOLO, a single convolutional network predicts the bounding boxes and class probabilities of that bounded boxes.
In this YOLO we take an image and splits into a grid and within each grid we take the m bounding boxes. Bounding box for each bounding box the network outputs a class probability and offset values of the bounding boxes. The bounding boxes probability is higher than the threshold value then it selected and used to identify the object within the image.
Advantages and disadvantages of YOLO:
1. YOLO is very much faster (45 frames per second) than all other object detection algorithms.
2. The main disadvantage of the YOLO algorithm is it can’t identify the small objects in the image. For instance the YOLO faces some difficulties to detect the flock of birds.
SSD- Single Shot MultiBox Detector:
In this Single Shot MultiBox Detector, we can do the object detection and classification using single forward pass of the network. Here the multibox is a name of the technique for the bounding box regression. It is used to detect the object and also classifies the detected object.

In this Single Shot Detectors we are using several components such as
- MultiBox.
- Priors.
- Fixed Priors.
Once we can observe the above diagram we performed a “Network Surgery” on the base network.
Basically the network surgery is nothing but we can remove the some layers from the base architecture and replace them with new layers. Sometimes just remove the parts and there is no need to replace them then when we are going to train our framework for object detection just both the weights of the new layers and base network are modified.
The it will be forms fully convolutional and eliminates the Convolutional and Pooling layers and replace with series of new layers(SSD) , new modules(Faster R-CNN) or some combination of two.
Advantages of SSD:
SSD gives a better balance between swiftness and precision. SSD runs a convolutional network on input image only one time and it computes a feature map.


