Gradient Descent & Stochastic Gradient Descent
The pre-requisites for this article:
1. Enough knowledge on the terms like Model parameters,Cost function
2. Calculus-First order derivatives(chain rule and power rule)
Gradient Descent is a FIRST ORDER OPTIMIZATION algorithm that is used to maximize or minimize the cost function of the model.As it uses the first order derivatives of the cost function equation with respect to the model parameters.We also have SECOND ORDER OPTIMIZATION techniques that uses second order derivatives which are called as “HESSIAN” to maximize or minimize the cost function,We will learn this Second Order Optimization in coming articles
As you saw the above definition looks so messy.I’ll make it easy,Just in layman terms Gradient Descent is an optimization technique used to update weights and bias(model parameters) to reduce cost function of the model
Let’s take a simple example,I believe that you all know how to build a model and predict the data.Assume that “y” is the actual output and “yi” is the value that our model predicts.if you thought that you are done then its your blunder.You have to check weather the model you built is correct or not for that what we will do is just calculate the difference between the predicted output(yi) and actual output(y)
y – yi ——–> eq(1)
To resolve the magnitude issues i.e, Not getting cancelled because of opposite signs we are squaring the eq(1) and as we want to calculate the loss for whole model so,let’s make it average for all “N” observations. And final substitution as we know that the predicted “yi” means (mxi+b).Substitute this in eq(1) finally we get


As the function is squared one then locus of all possible points leads to a graph of parabola.Here f(m,b) is the cost function in terms of m(weights) and b(bias),hence cost function is dependent of m,b values and parabolic in shape.So,to optimize these values which directly effects the cost function is needed.Thus Gadient Descent comes into play.we have to know with what change in (m,b) values cost function can be reduced which indirectly tells the slope(ratio of change in y to change in x).Derivatives are very handy in such scenarios
The Power Rule:

The Chain Rule:

So keeping the above formula in mind let’s find the first order derivatives of the cost function with respect to m,b

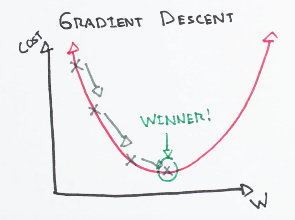
We got the above equation which depicts what is the change in cost function with change in model parameters.let’s assume initial weights and bias are selected randomly so we got the cost function at a point “1” some where on the parabolic curve as shown in below figure. Which are not an optimum values of parameters. In order to get minimum cost function we have to move to local minimum fig(4)


To minimize the cost function we find the derivative of it with respect to model parameters and reduce this values from those original values.Here a new term called Learning rate comes in to play.what this term exactly mean is with what step value the cost function point has to move in which direction.As in the figure above for every iteration the cost function is approaching minimum point which in turn reduces the cost function of the model.Number of iteration and value of learning rate(optimal value=0.001) are tunable. After some iterations the values of weights and bias won’t change much then we can stop the iterations
Code:
def modify_weights(m, b, X, Y, learning_rate): m_derivative = 0 b_derivative = 0 N = len(X) for i in range(N): # Then Calc. partial derivatives w.r.t “m”: -2x(y - (mx + b)) m_derivative += -2*X[i] * (Y[i] - (m*X[i] + b)) # Then Calc. partial derivatives w.r.t “b”: -2(y - (mx + b)) b_derivative += -2*(Y[i] - (m*X[i] + b)) #Now We subtract them as the derivatives point in direction of steepest ascent m -= (m_derivative / float(N)) * learning_rate b -= (b_derivative / float(N)) * learning_rate return m, b
Categories of Gradient Descent
Gradient Descent have some issues regarding computation resources hence some advancements are done to the existing optimization techniques.Those are following
Stochastic Gradient Descent
Mini- Batch Gradient Descent
Batch Gradient Descent
In traditional gradient descent algorithm for every iteration we calculate the loss function for all samples and average it to compute overall model’s cost function which is very expensive in terms of computation power. So, as to reduce the burden on the processing engine two techniques were introduced to over come the limitations of typical gradient descent.
Stochastic Gradient Descent
The term ‘stochastic‘ implies a system or a process that associated with a random probability. Hence, in Stochastic Gradient Descent, Randomly few samples are selected instead of the whole population(data set) for each iteration. In Gradient Descent,A term called “batch” which indicates the total no.of samples from whole population(dataset) which is used to calculate the gradient for each iteration. In traditional Gradient Descent optimization technique,Batch is taken to be the whole dataset in Batch Gradient Descent,Using the entire dataset is really helpful for getting to the minima in less random manner, but what happens is when our datasets are huge there arises many problems.
Let’s say, we have a millions of samples in your dataset, And if we use a traditional Gradient Descent optimization technique,computing all one million samples for one iteration while performing the Gradient Descent, and for every iteration we have to do the same until the minima is reached. Hence, we end up wasting a lot of time and computation power
But the above limitation can be overcome by Stochastic Gradient Descent. In SGD, it utilizes only one single sample(a batch size of one) to compute each iteration. Every time the sample is randomly shuffled and selected for performing the iteration. So, in Stochastic Gradient Descent, we compute the gradient of the loss function of a single sample at each iteration instead of the sum of the gradient of the cost function of all the samples(whole dataset).
In Stochastic Gradient Descent,One random set of samples from the dataset is chosen for each iteration, the path taken by the technique to reach the minima is usually noisier than your traditional Gradient Descent optimization technique as shown in the below figure. But path taken by the algorithm does not matter much, as long as we reach the minima with efficient shorter training time.

SGD is preferred over Batch Gradient Descent for optimizing a learning algorithm in most scenarios.Because,Even though it takes more no.of iterations to reach the minima than traditional Gradient Descent, it is still computationally effective than any other optimization technique
Mini-Batch Gradient Descent:
In mini-batch gradient technique it divides the training dataset into small batches that are used to evaluate model’s error and update model’s coefficients.
Mini-batch gradient descent is a blend of characteristics like the efficiency of batch gradient descent and the robustness of stochastic gradient descent(SGB) . This is the most commonly used technique in the field of deep learning.

Batch Gradient Descent:
Batch gradient descent technique calculates the error for each example in the training dataset, but only updates the model after all training examples are computed.
Training epoch is One cycle through the entire training dataset . Therefore, it is often said that it updates model at the end of each training epoch.