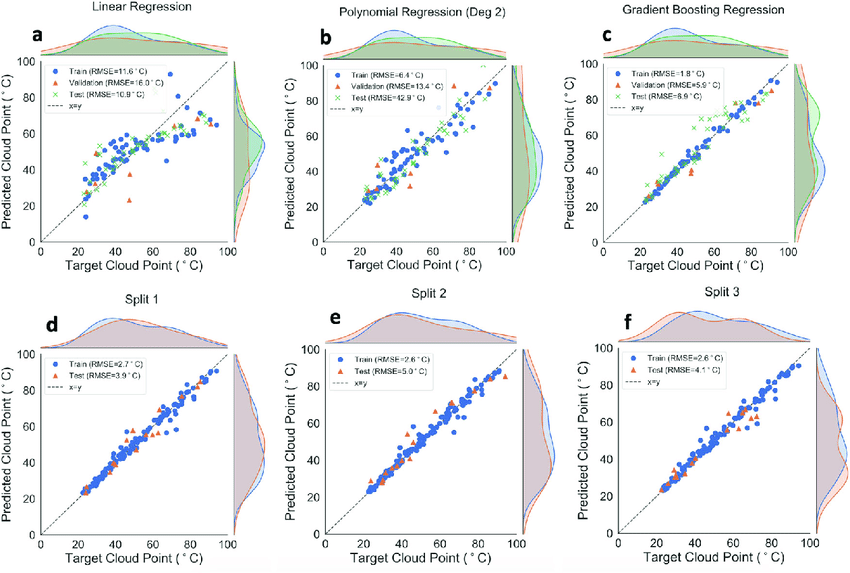
Lasso Regression
It is similar to the ridge regression , the Lasso (Least Absolute Shrinkage and Selection Operator) it is penalizes the absolute size of regression coefficients and it reduces the variability and increase the accuracy. Lasso is mainly used when we are having the large number of features because Lasso does the feature selection. The lasso regression will give the results in sparse matrix with less coefficients and some co-efficient becomes zero.

In this we are having the feature selection It is also called as L1 regularization technique. Lets take a dataset and perform the Lasso regression ,
The implementation of Lasso regression is:
In this dataset we are having the 5 columns in which 4 are independent variables and 1 dependent variable.
Import the necessary libraries numpy , pandas , and matplotlib
Import numpy as np Import pandas as pd Import matplotlib.pyplot as plt %matplotlibinline Import sklearn
We can load the data by using read_csv function
Data=pd.read_csv(“D:\\ML CSV\\classi\\50_Startups.csv”) Data=pd.read_csv(“path of data.name of data.csv) Data.head(4)
Output:

By using head function we can print the first five rows of our dataset.
Now, we can separate the features and target using iloc function.
X=Data.iloc[:,:-2].values Y=Data.iloc[:,1:].values X Y
Here we can train our model by using train_test_split method. We can import this function by sklearn.
from sklearn.model_selection import train_test_split X_train,X_test,Y-train,Y_test=train_test_split(X,Y,test_size=0.2,random_state=1)
After training we have to fit to our model i.e Ridge regression , for this we can import our model some required parameters mean squared error , r2_score etc.
from sklearn.linear_model import Lasso from sklearn.metrics import mean_squared_error,r2_score r=Lasso(alpha=0,normalize=True,fit_intercept=True) Lasso=r.fit(x_train,y_train) Lasso
Output:
Lasso(alpha=1, copy_X=True, fit_intercept=True, max_iter=1000, normalize=True, positive=False, precompute=False, random_state=None, selection=’cyclic’, tol=0.0001, warm_start=False)
After training we can predict the test values
Y_pred=lr.predict(x_test) Y_pred
Output:
array([[103018.44429493 132592.11934796 132468.65602221 71999.33875517 178552.30932391 116134.91676856 67852.78695145 98781.77433371 113974.6582454 167941.19447351]83305081.76519412
After predicting we can check the mean_squared_error and r2_score using metrics functions.
mean_squared_error(y_test,y_pred) r2_score(y_test,y_pred)
Output:
Mean squared error : 83305081.76519412
R2_score : 0.9348614986438546