What are the various loss functions used in different Regression methods in Machine Learning?
There are 5 types of Regression losses used in Machine Learning. They are Mean Square error or Quadrature Loss or L2 Loss, Mean Absolute Error or L1 Loss, Huber Loss or Smooth Mean Absolute Error, Log-Cosh Loss and Quantile Loss. Let us see in brief,
1. Mean Square Error, Quadratic loss, L2 Loss
MSE (Mean Squared Error) represents the difference between the original and predicted values which are extracted by squaring the average difference over the data set. It is a measure of how close a fitted line is to actual data points. The lesser the Mean Squared Error, the closer the fit is to the data set. The MSE has the units squared of whatever is plotted on the vertical axis.


2. Mean Absolute Error, L1 Loss
Mean absolute error is measured as the average of sum of absolute differences between predictions and actual observations. It measures the magnitude of error without considering their direction. MAE needs more complicated tools such as linear programming to compute the gradients. MAE is more robust to outliers since it does not make use of square.
MAE gradients with respect to the predictions. The gradient is a step function and it takes -1 when Y_hat is smaller than the target and +1 when it is larger.
The gradient is not defined when the prediction is perfect, because when Y_hat is equal to Y, we cannot evaluate gradient. It is not defined.


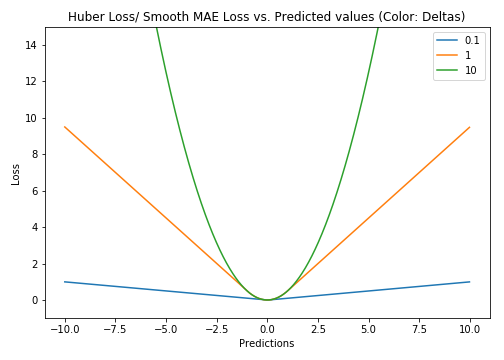
3. Huber Loss, Smooth Mean Absolute Error
Huber loss is less sensitive to outliers in data. It can be also differentiable at 0. Actually, it is an Absolute error but when the Error is small then it becomes to Quadratic Loss. Size of an Error to become Quadratic loss depends upon the tuning of Hyperparameter. Huber loss becomes equal to MAE when 𝛿 ~ 0 and MSE when 𝛿 ~ ∞ (large numbers.)


Plot of Hoss Loss (Y-axis) vs. Predictions (X-axis). True value = 0
4. Log-Cos h Loss
Log-cos h is a function used in regression methods which are smoother than L2 or Mean squared error. Log-cosh is the logarithm of the hyperbolic cosine function of the prediction error.


Log-cos h loss is not perfect. It suffers from the gradient and hessian for very large off-target predictions being constant, therefore resulting in the absence of splits for XGBoost.
5. Quantile Loss
Quantile-based regression aims to estimate the conditional “quantile” of a response variable given certain values of predictor variables. Quantile loss is actually just an extension of MAE

γ is the required quantile and has value between 0 and 1.