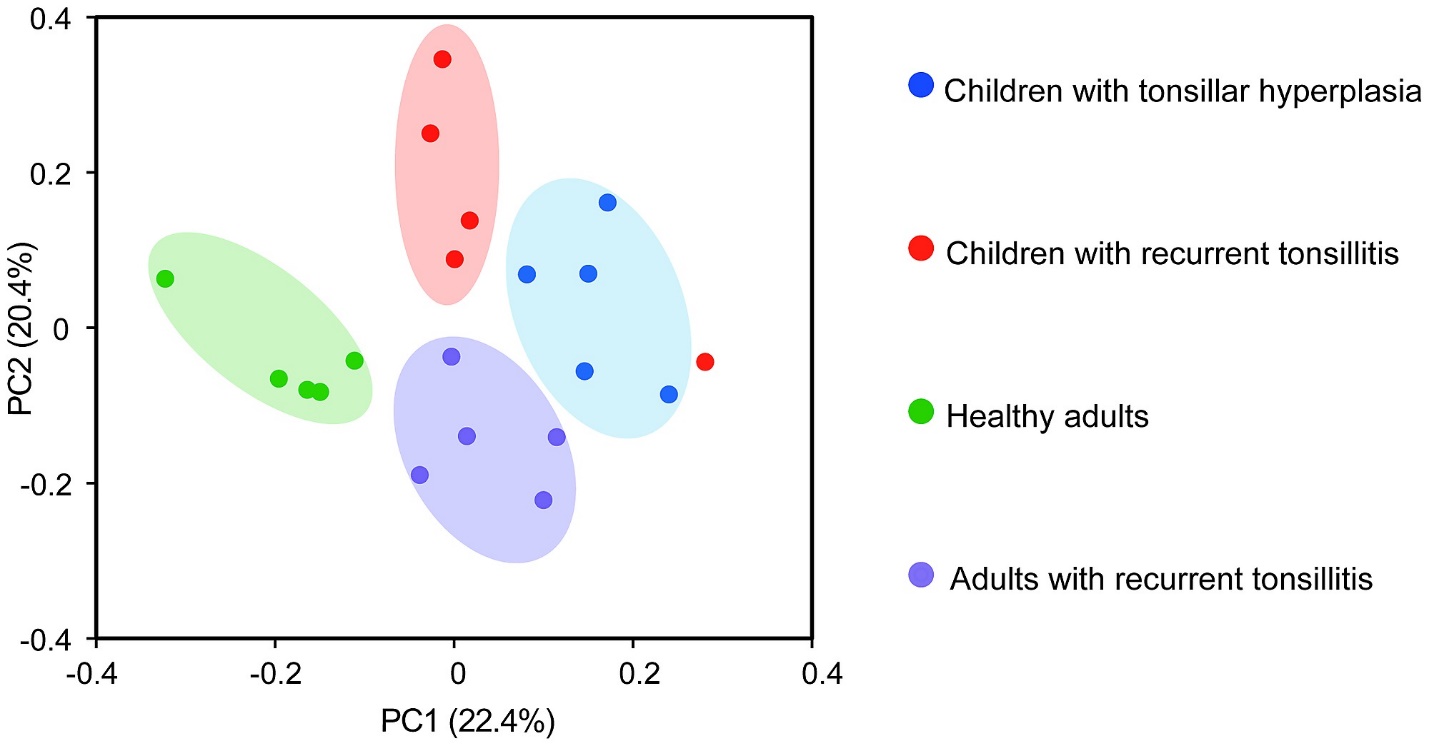
What do you mean by Binning in Machine Learning? What are the differences between Fixed width binning and Adoptive binning?
Data binning, bucketing is a data pre-processing method used to minimize the effects of observation errors. Binning is the process of transforming numerical variables into categorical counterparts. Binning improves accuracy of the predictive models by reducing the noise or non-linearity in the dataset. Finally, binning lets easy identification of outliers, invalid and missing values of numerical variables.
Binning is a quantization technique in Machine Learning to handle continuous variables. It is one of the important steps in Data Wrangling.

There are two types of binning techniques:
1. Fixed-Width Binning
2. Adaptive Binning
1. Fixed-Width Binning
We manually create fix width bins on the basis of some rules and domain knowledge.
age = [12, 15, 13, 78, 65, 42, 98, 24, 26, 38, 27, 32, 22, 45, 27]
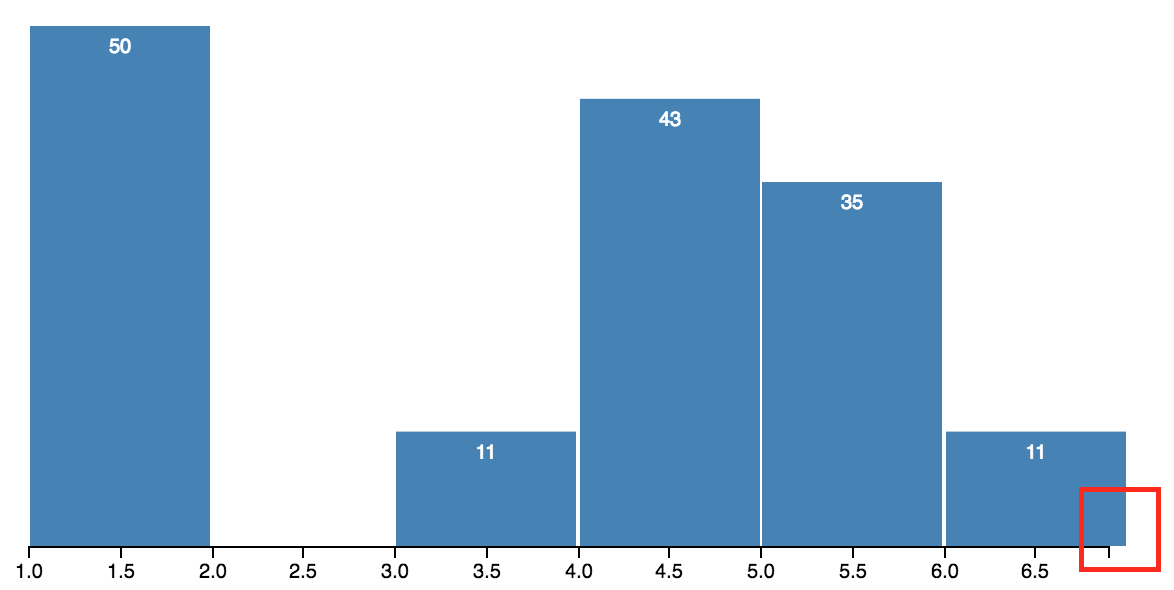
Now, let’s create bins of fixed width (say 10):
bins = [0 {0-9}, 1 {10-19}, 2 {20-29}, 3 {30-39}, 4 {40-49}, 5 {50-59}, 6 {60-69}, 7 {70-79}, 8 {80-89}, 9 {90-99}]
After binning, our age variable looks like this:
age = [1, 1, 1, 7, 6, 4, 9, 2, 2, 3, 2, 3, 2, 4, 2]
In this way, all the 15 values will fit in above 10 ranges / bins. Think of a dataset containing thousands of values in the age column instead of just 15! How useful it would be in this case.

2. Adaptive Binning
In Adaptive Binning, data distribution itself decides bin ranges for itself. No manual intervention is required. So, the bins which are created are uniform in terms of number of data points in it.