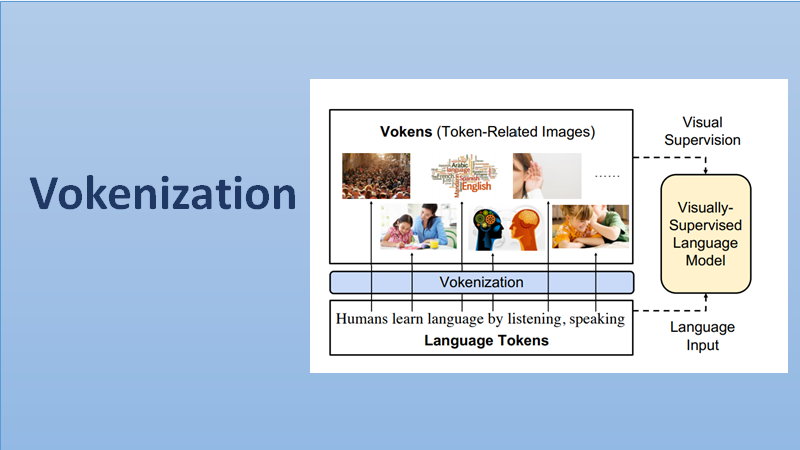
“Vokenization” and its importance in NLP
Humans learn language by listening, speaking, writing, reading, and also, via interaction with the multimodal real world. Current language pre-training frameworks show the efficiency of text-only self-supervision. To address this challenge, the researchers from UNC-Chapel Hill introduced a new technique that gets the context of the image right. Although self-supervised frameworks like BERT and GPT set new standards of natural language understanding, they did not borrow grounding information from the external visual world.
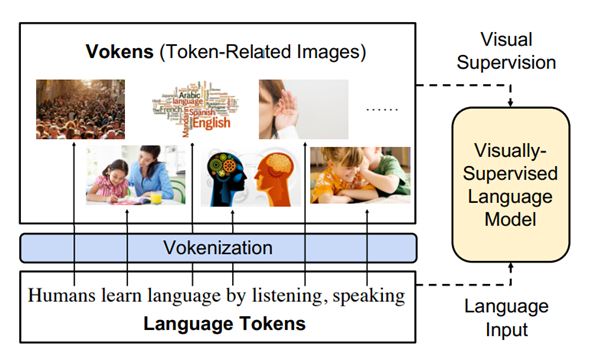
The main reason delaying this exploration is the large divergence in magnitude and distributions between the visually-grounded language datasets and pure-language corpora. Hence, they designed a technique named “vokenization” that generalizes multimodal alignments to language-only data. It contextually maps language tokens to their related images which we call as “vokens”. The “vokenizer” is trained on relatively small image captioning datasets and then apply it to generate vokens for large language corpora. Using these contextually generated vokens and training our visually-supervised language models there would be constant improvements over self-supervised alternatives on multiple pure-language tasks such as GLUE, SQuAD, and SWAG.
Vokenization step by step process:
- Each token in a sentence is assigned with a relevant image.
- From a set of images retrieve an image regarding a token-image-relevance scoring function.
- This scoring function, parameterized by θ, measures the relevance between the token in the sentences and the image.
- In the sentence is realized as the image that maximizes their relevance score.
Self-supervision drives the on textual language representation learning without considering explicit connections. As demonstrated above, the researchers visually supervised the language model with token-related images. These images are called vokens (visualized tokens). Vokenization helps to generate them contextually.
The whole process of vokenization, can be summarised ad Lying in the core of the vokenization process is a contextual token-image matching model. The model takes a sentence and an image as input, and the sentence is composed of a sequence of tokens. The result would be the relevance score between the token and the image while taking the whole sentence as a context.

The authors stated that when the unique image is tough to define, the vokenizer considers the non-concrete tokens (e.g., “by”/“and”/“the”) to relevant images. This related visual information helps understand the language and leads to the improvement


