What are the different Gradient Descent implementations/ methods?
Ans. There are different implementations of Gradient Descent which are used for minimizing cost functions.
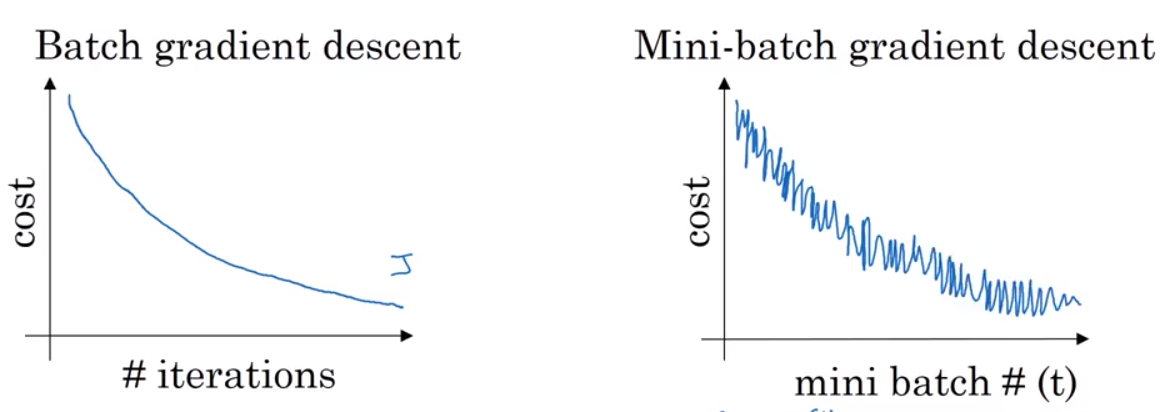
Batch Gradient Descent: It processes all the training examples for each iteration of gradient descent. If the number of training examples is large, then batch gradient descent is very expensive. So, in case of large training examples we prefer to use stochastic gradient descent or mini-batch gradient descent.

Stochastic Gradient Descent: This is a type of gradient descent which processes 1 training example per one iteration. Hence, the parameters are being updated even after one iteration. This is quite faster than batch gradient descent. But again, when the number of training examples is large, even then it processes only one example which can be additional overhead for the system as the number of iterations will be quite large.
Hence, we go for Mini Batch Gradient Descent.

Mini Batch gradient descent: It which works faster than both batch gradient descent and stochastic gradient descent. Here b examples where b<m are processed per iteration. So even if the number of training examples is large, it is processed in batches of b training examples in one go. Thus, it works for larger training examples and that too with lesser number of iterations.



